









LaserNet:一种高效的自动驾驶概率三维目标探测器
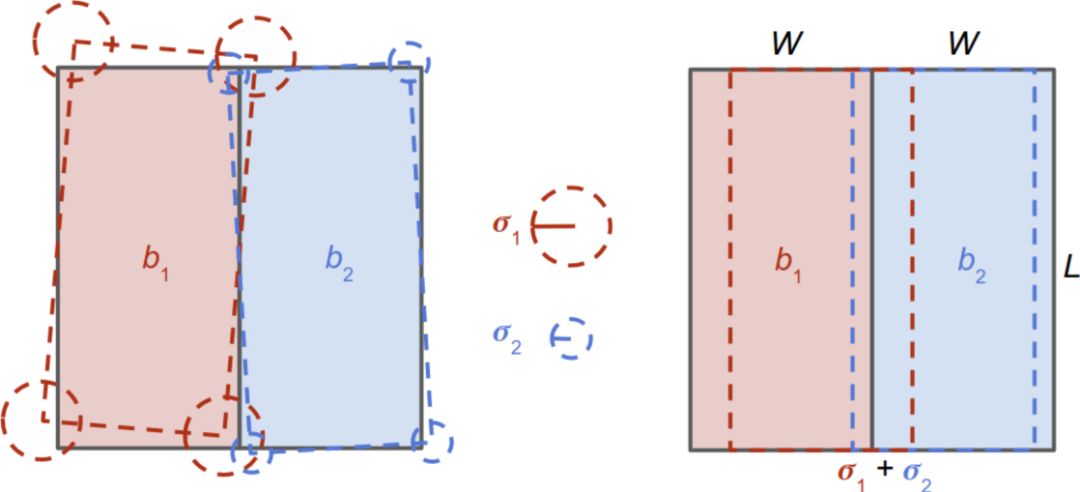
上图为自适应NMS。在两辆车并排放置的情况下,左边的虚线描述了产生的一组可能的预测。为了确定边界框是否封装了唯一的对象,使用预测的方差(如中间所示)来估计最坏情况下的重叠(如右图所示)。在本例中,由于实际重叠小于估计的最坏情况重叠,因此将保留这两个边界框。
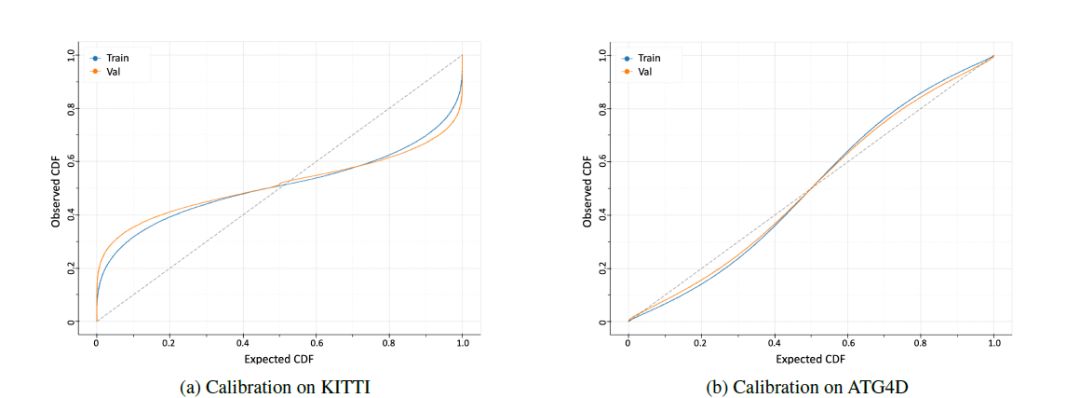
上图为在训练集和验证集上的边界框上的预测分布的校准的图。结果表明,该模型不能学习KITTI上的概率分布,而能够学习较大的ATG4D上的分布。
【实验结果】

上表显示了与其他最先进的方法相比,LaserNet在验证集上的结果。像KITTI基准一样,我们计算了汽车0.7 IoU和自行车及行人0:5 IoU的平均精度(AP)。在这个数据集上,LaserNet在0-70米范围内表现优于现有的最先进的方法。此外,LaserNet在所有距离上都优于LiDAR-only方法,只有在附加图像数据提供最大价值的长距离上,车辆和自行车上的LiDAR-RGB方法优于LaserNet。
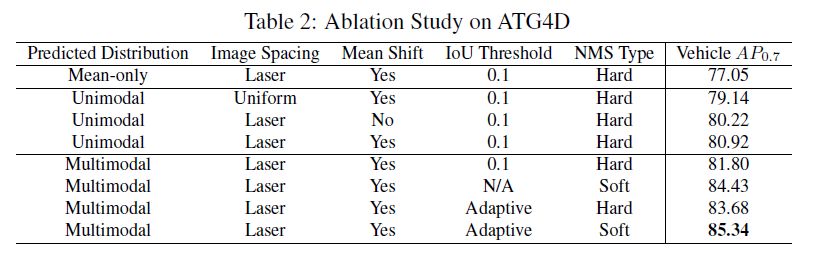
对ATG4D数据集进行消融研究,结果如上表所示。
预测概率分布。预测概率分布最大的改进是预测边界框架的分布。当仅预测平均边界框时,公式(6)为简单平均,公式(9)为框角损失。此外,边界框的得分在本例中是类概率。实验结果表明,性能上的损失是由于概率与边界框架的准确性没有很好地相关性导致的。

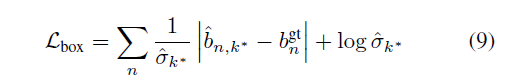
图像形成:Velodyne 64E激光雷达中的激光器并不是均匀间隔的。通过使用激光id将点映射到行,并在传感器捕获数据时直接处理数据,可以获得性能上的提高。
均值漂移聚类:每个点独立地预测边界框的分布,通过均值漂移聚类将独立的预测组合起来实现降噪。
非极大值抑制:当激光雷达的点稀疏时,有多个边界框的配置可以解释观测到的数据。通过预测各点的多模态分布,进一步提高了该方法的查全率。在生成多模态分布时,使用具有严格阈值的NMS是不合适的。或者,我们可以使用软NMS来重新评估置信度,但是这打破了对置信度的概率解释。通过自适应NMS算法,保持了概率解释,并获得了更好的性能。

对于自动驾驶而言,运行时性能同样重要。上表比较了LaserNet(在NVIDIA 1080Ti GPU上测量)和KITTI上现有方法的运行时的性能。Forward Pass是指运行网络所花费的时间,除Forward Pass外,总时间还包括预处理和后处理。由于在一个小的密集的范围视场内处理,LaserNet比目前最先进的方法快两倍。
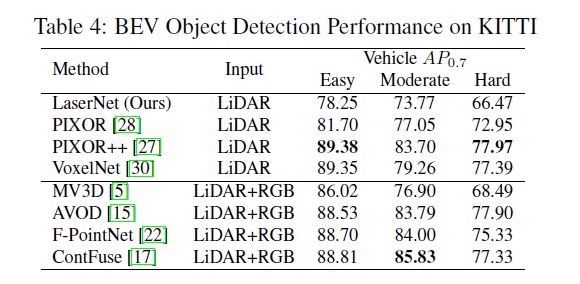
使用训练集中的5,985个扫描点训练网络,并保留其余的扫描以进行验证。使用与之前相同的学习时间表对网络进行5万次迭代训练,并在单个GPU上使用12个批处理。为了避免在这个小的训练集上过度拟合,采用数据增强手段随机翻转范围图像,并在水平维度上随机像素移动。在这样一个小的数据集中,学习边界框上的概率分布,特别是多模态分布是非常困难的。因此,训练网络只检测车辆并预测边界框上的单峰概率分布。如上表所示,我们的方法在这个小数据集上的性能比当前最先进的鸟瞰图检测器差。

 分享
分享








最新活动更多
-
4月26日立即报名 >> 【线上研讨会】TDK模块化电容器、电能质量解决方案
-
4月30日免费下载 >> SPM31智能功率模块助力降低供暖和制冷能耗,打造可持续未来!
-
4月30日限时免费下载>> 高动态范围(eHDR)成像设计指南
-
5月10日立即下载>> 【是德科技】精选《汽车 SerDes 发射机测试》白皮书
-
5月28日立即观看>> 【在线研讨会】Ansys镜头点胶可靠性技术及方案
-
5月31日立即报名>> 【线下论坛】新唐科技2024未来创新峰会
推荐专题







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论